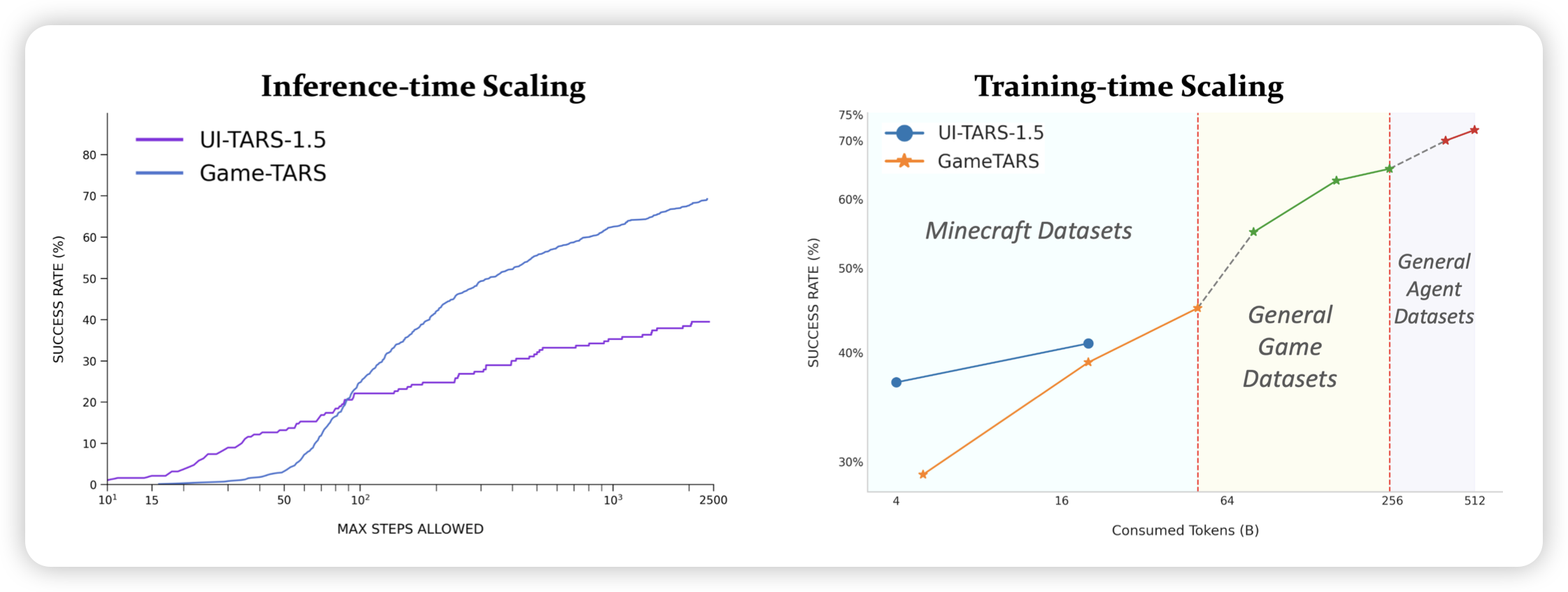
Game-TARS: Pretrained Foundation Models for Scalable Generalist Multimodal Game Agents
推荐我们组的工作:我们发现已有的cua几乎都是基于预定义的动作空间,比如鼠标点击、键盘打字。这契合vlm的性质(每个step一张图)。但如果我们有video model,能不能像人一样,每秒看30次屏幕,然后直接给出最原始的操作逻辑(鼠标移动是dx dy,键盘操作是press/release)?
我们在game agent场景做了实验,直接训练在接近1000个游戏上训练,并发现:raw action model在前期的表现非常差,几乎什么也做不了;但随着训练量的增加,模型逐渐“领悟”了原始动作空间的含义,学会了微调鼠标来瞄准、加速跑、甚至落地水等非常高级的技巧,这事实上也是预定义的动作空间永远无法表征的
Tongyi DeepResearch Technical Report
AgentFold: Long-Horizon Web Agents with Proactive Context Management
PARALLELMUSE: Agentic Parallel Thinking for Deep Information Seeking
Repurposing Synthetic Data for Fine-grained Search Agent Supervision
今天qwen大爆发,又连着爆出来好多篇search agent论文。这几篇工作的侧重点各有不同
前几天才大爆发一次,这波怎么又爆发出来这么多论文...
OSWorld-MCP: Benchmarking MCP Tool Invocation In Computer-Use Agents
最近出了一些cua里加mcp的工作,其中这篇是感觉比较好的。这不是一个方法工作,而是一个benchmark,作者基于osworld开发了157个mcp工具,并测试模型在有这些工具的情况是否会做得更好。作者初步测试发现,大多数情况下,已有的这些gui agent实际上给了mcp工具以后会更差。