Scaling Up RL: Unlocking Diverse Reasoning in LLMs via Prolonged Training
上个月nvidia刚发了一篇纯文本的rl调优指南(AceReason-Nemotron 1.1),这次又发了一篇。消融了reward、clip等变量,给出了一些训练认知。
赛马?
Voxtral
看名字就感觉是mixtral干的,果然,这个是mixtral新出的语音理解模型,32k上下文,差不多对应40min音频。
语音理解这个领域好像工作一直挺少的,不知道为什么
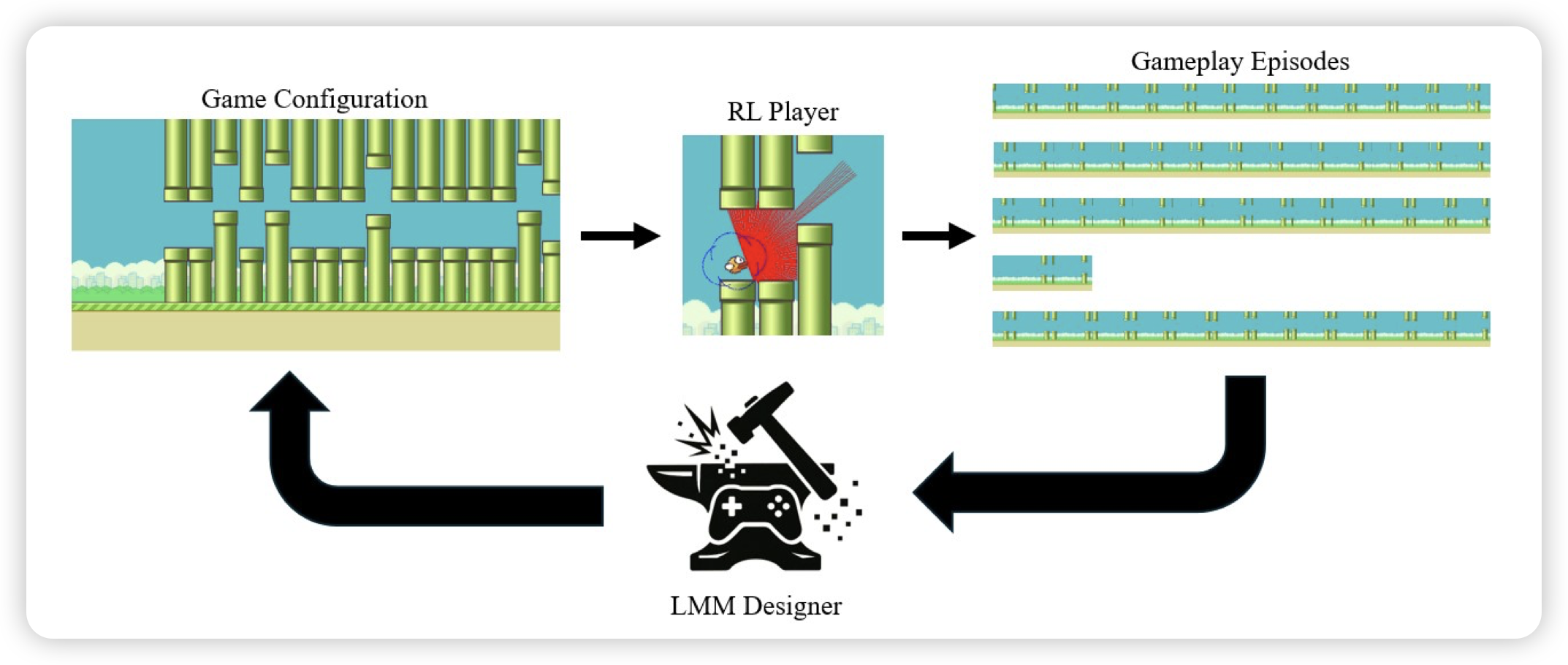
Fly, Fail, Fix: Iterative Game Repair with Reinforcement Learning and Large Multimodal Models
Nvidia的工作:如果AI已经可以作为game agent做得还不错了,那能不能用agent测试游戏设计得好不好呢?作者发现,在现在vlm进一步提升了game agent水平以后,这已经成为了可用的东西。
我记得我很早就看到过类似的想法,但可能确实现在到了可用的地步