真有1000篇…但说实话,最火的是没论文的sora2
LLaVA-OneVision-1.5 : Fully Open Framework for Democratized Multimodal Training
真的泪目,llava这个系列还在更新。时隔快一年,开源的训练数据涨到了85M midtrain,22M instruction following,训完以后在防守性的vlm benchmark上表现都很好
曾经也是和qwen-vl一个热度的东西呀
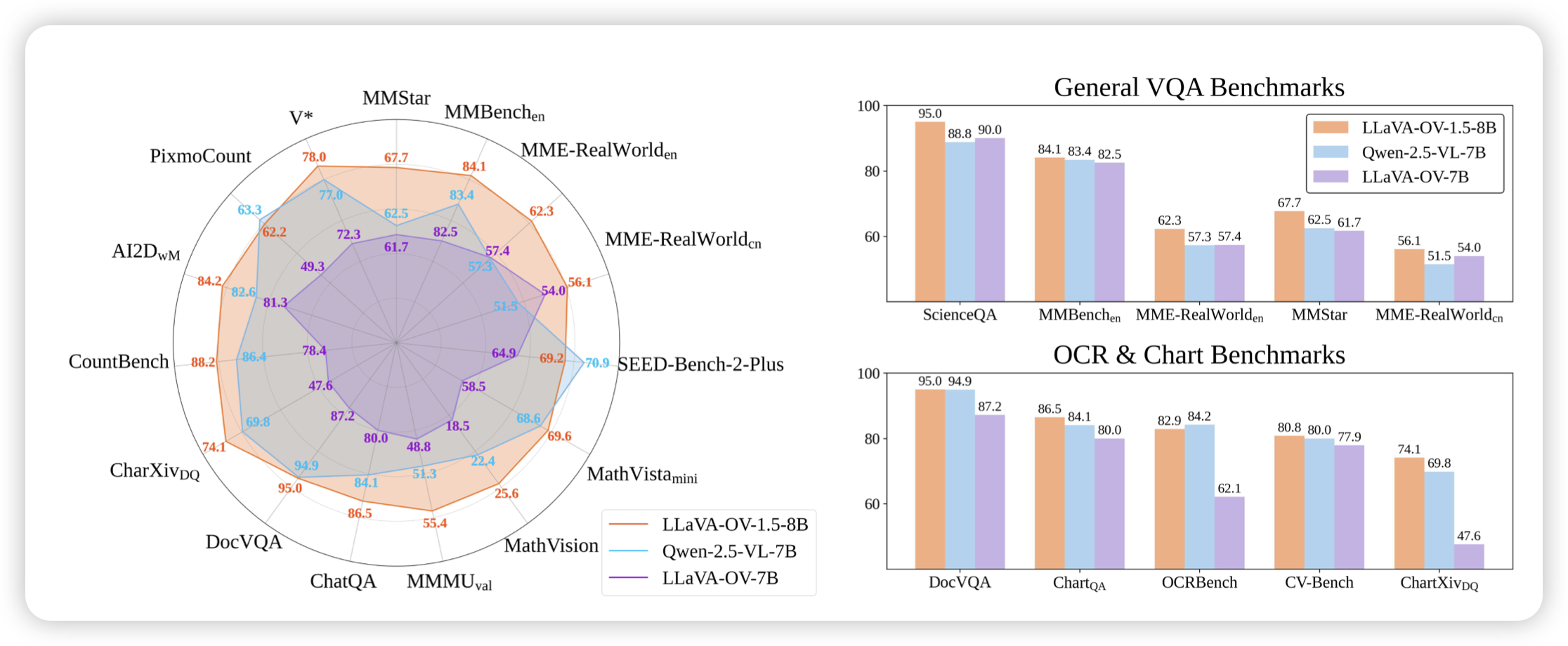
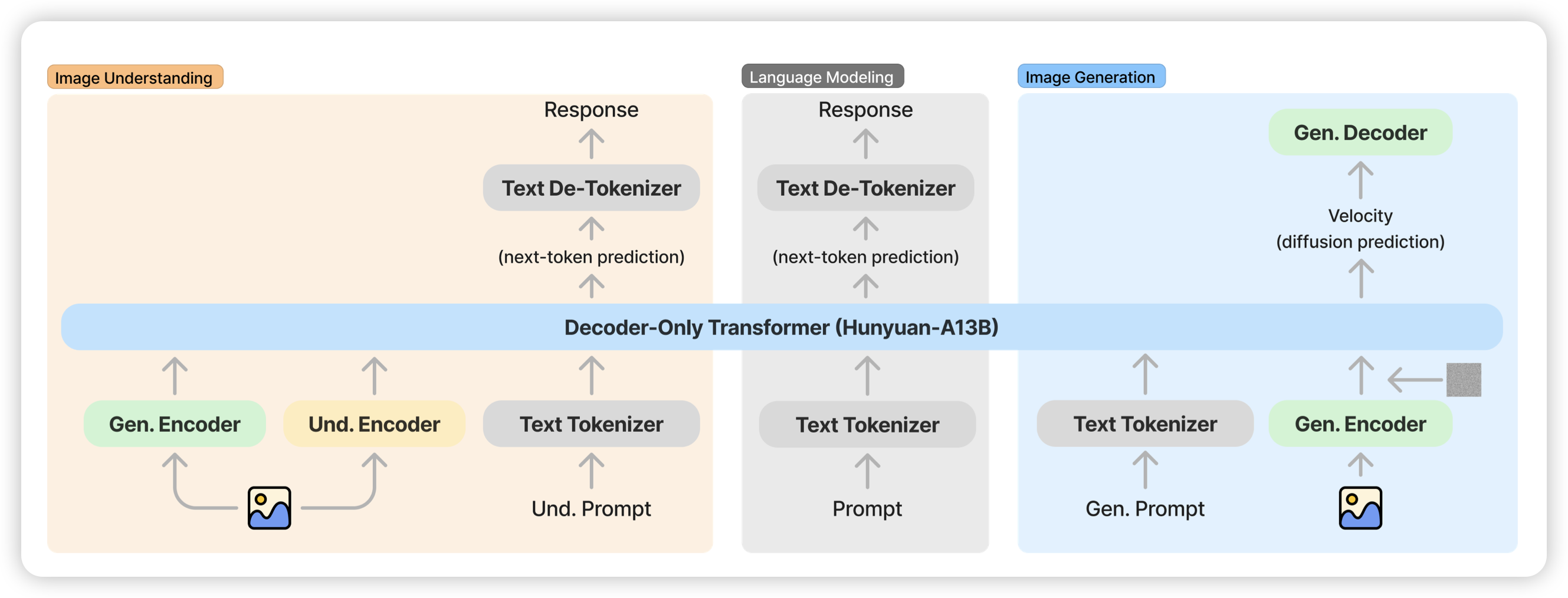
HunyuanImage 3.0 Technical Report
腾讯出的生成理解统一模型,类似于古老的janus结构,用了两种image encoder,总体decoder部分做成了80A13的级别
但是只开源image gen module是什么操作
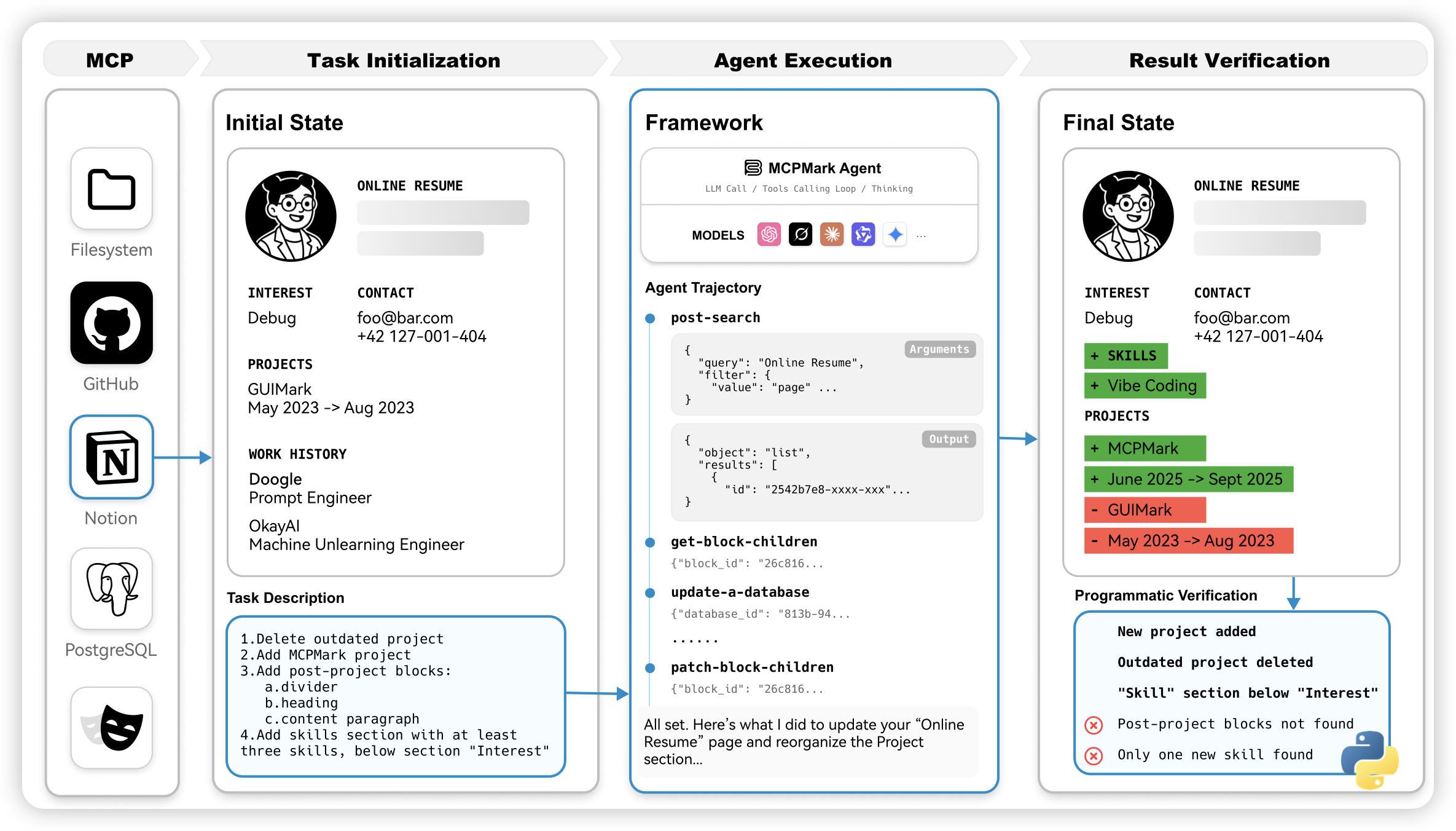
MCPMark: A Benchmark for Stress-Testing Realistic and Comprehensive MCP Use
印象中是一个挺老的benchmark了,但是今天才挂出来。作者找到了8个真实世界的app,然后是真的在上面注册账号的形式来出题和verify,做了127道比较solid的mcp能力检测benchmark
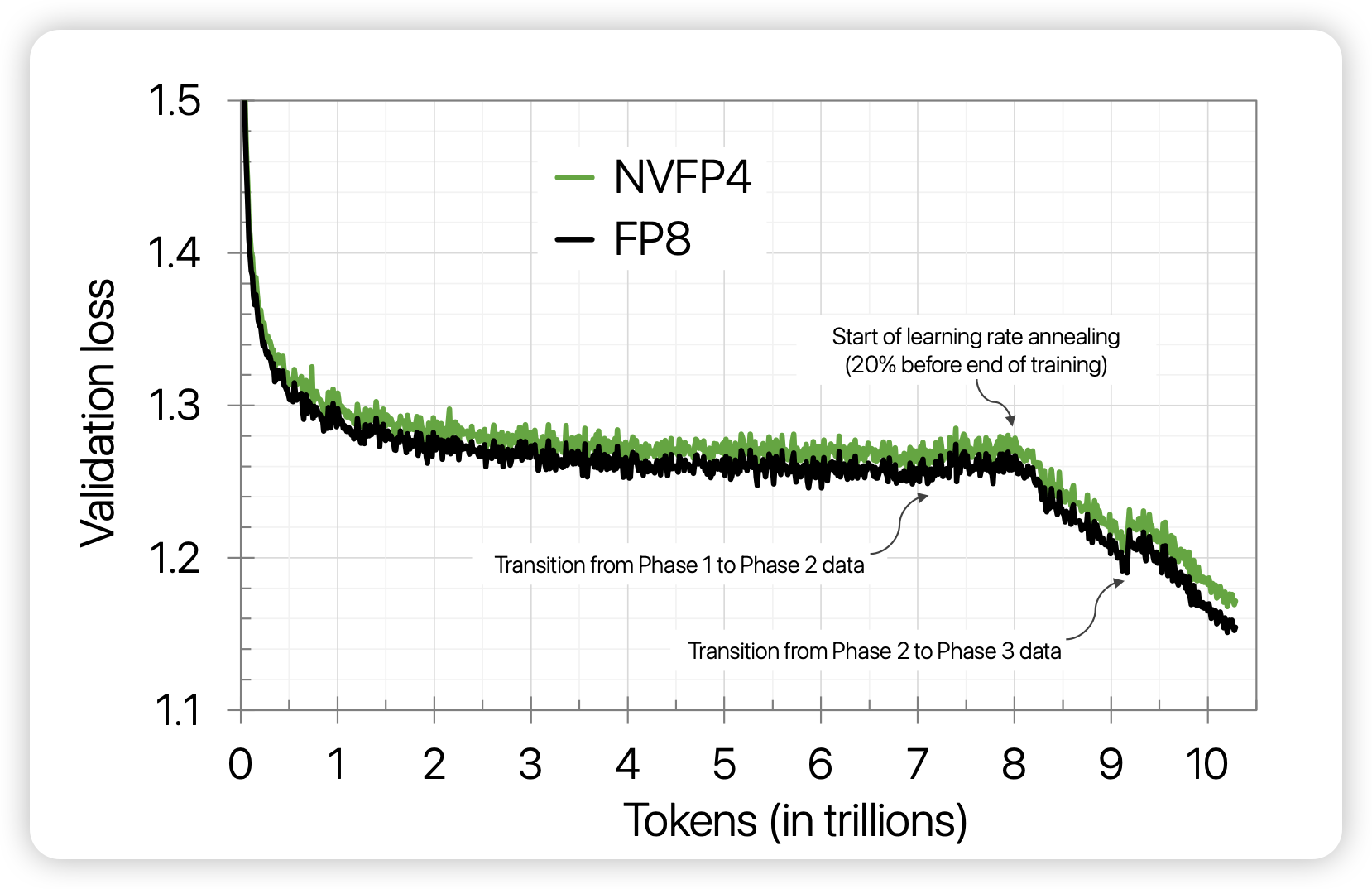
Pretraining Large Language Models with NVFP4
一篇nvidia秀肌肉的文章,但是肌肉确实大。当中国芯还在对接w4a8时,nvidia直接做了fp4的训练(不是量化推理)。为了证明他们真的能训,他们甚至训了10T token
有卡随便玩…大哥累了研究研究fp4怎么了
Training Agents Inside of Scalable World Models
这篇工作只有3个作者,内容却挺nb的。作者在一个minecraft视频生成模型里训练agent,最终在真实游戏里测试挖到了钻石,agent全程都没有和真实世界做过交互
minecraft应该是最好获得数据的3d游戏了,在这个游戏上如果train in world model是work的,那么才有可能在真实世界work。
不过不同环境有各自的复杂性,作者用了2540h minecraft视频可以在这个场景work,别的场景又不知道需要多少数据了

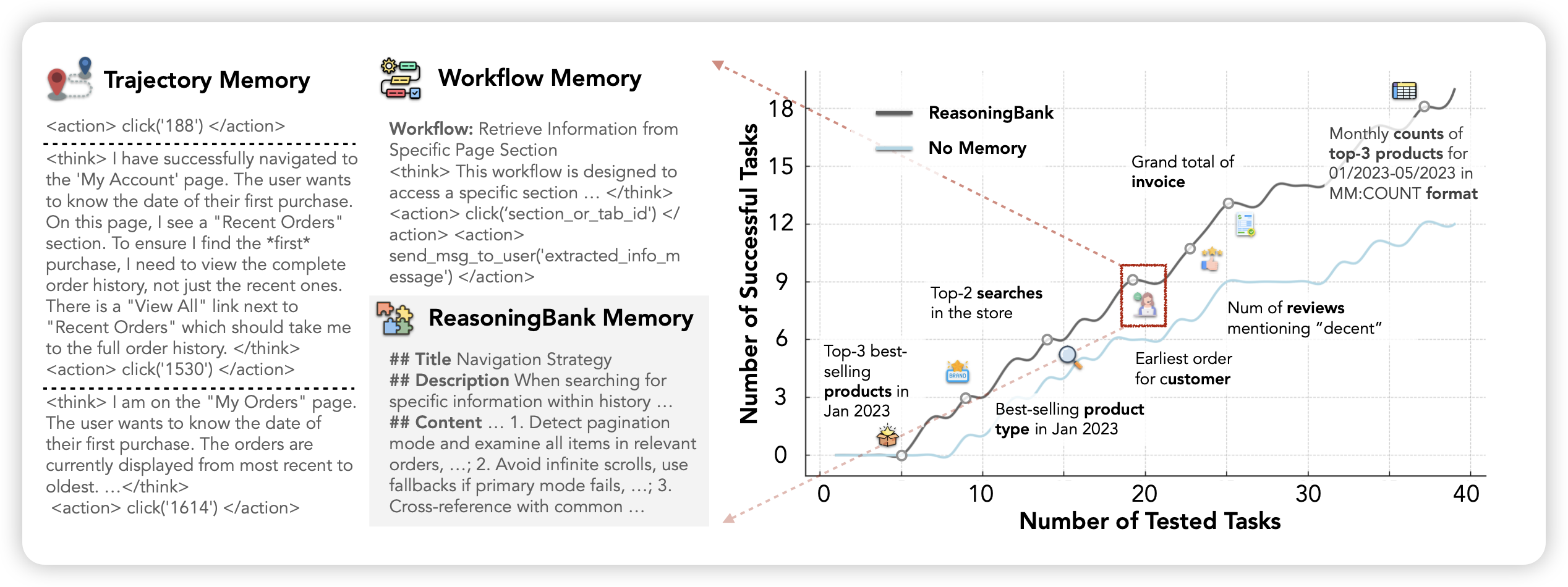
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
这篇工作中,作者讨论了Agent在interaction rounding scaling到更多时,模型往往不能利用起前面的好的或者坏的经验。作者设计了一套框架,可以让模型随着测试逐渐积累memory,再后面的题里回放前面题成功/失败的经验,使得模型随着测试的进行,变得越来越好