今天好像是nvidia发布会,出来了好多篇nv的论文
LongCat-Flash-Omni Technical Report
meituan最近猛猛发力了,接连出了flash,今天又出了flash-omni。这篇工作虽然叫flash,但其实是560 A27B
话说我最近才知道这个是”龙猫“,我之前一直以为是long来着...
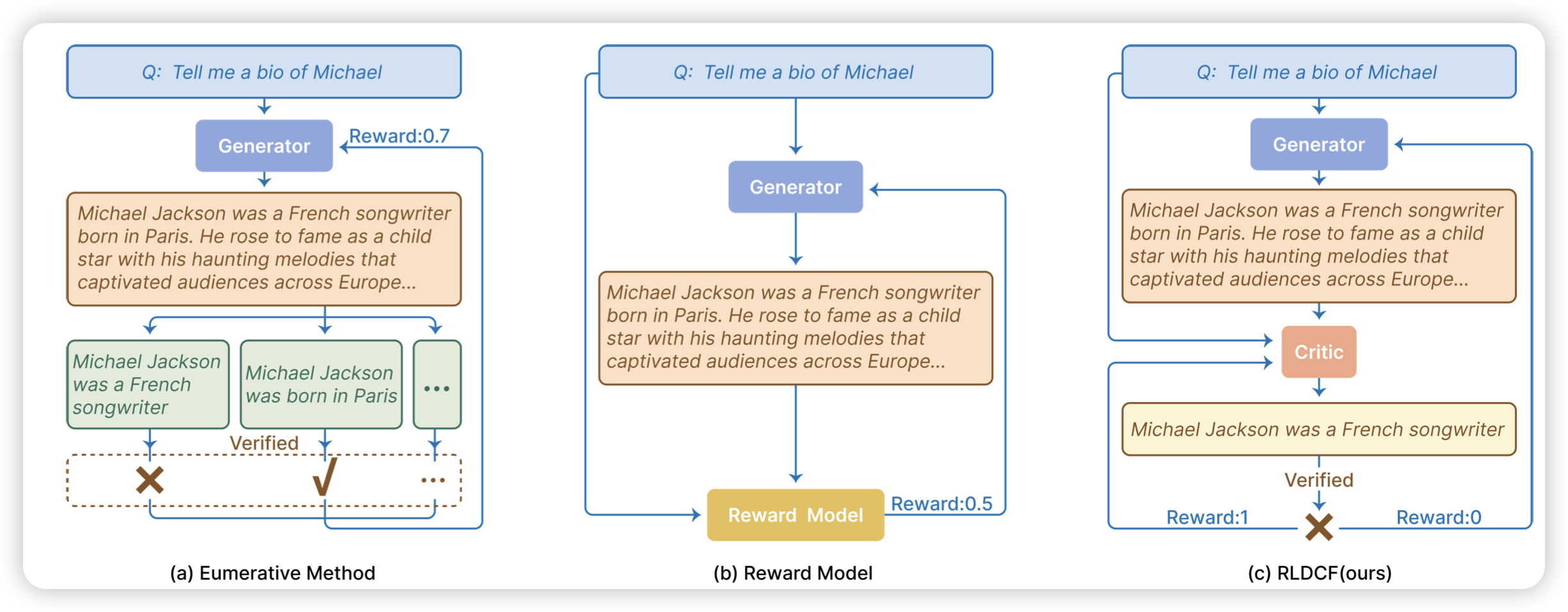
RLAC: Reinforcement Learning with Adversarial Critic for Free-Form Generation Tasks
这篇工作很有意思,作者发现传统的rl里面的reward model一般都是和policy独立训练的,所以他们之间不能互相交互。而作者把这个过程建模成了一个对抗过程:
- policy给个回答
- critic说出来原答案的一个更好验证的子集(rubric)
- 有一个另外的、不训练的validator,检测:1)rubric是否和原答案一致。2)rubric是否是通过
通过validator的最终裁决,可以同时给到actor和critic的得分,然后两者各自通过dpo训练。这个过程是把critic建模成actor的一个伴生检测器,一直学习去找到actor最薄弱的地方
感觉和下面那个有点像,这个领域应该也是有人提过,但好像一直没有人把它做work
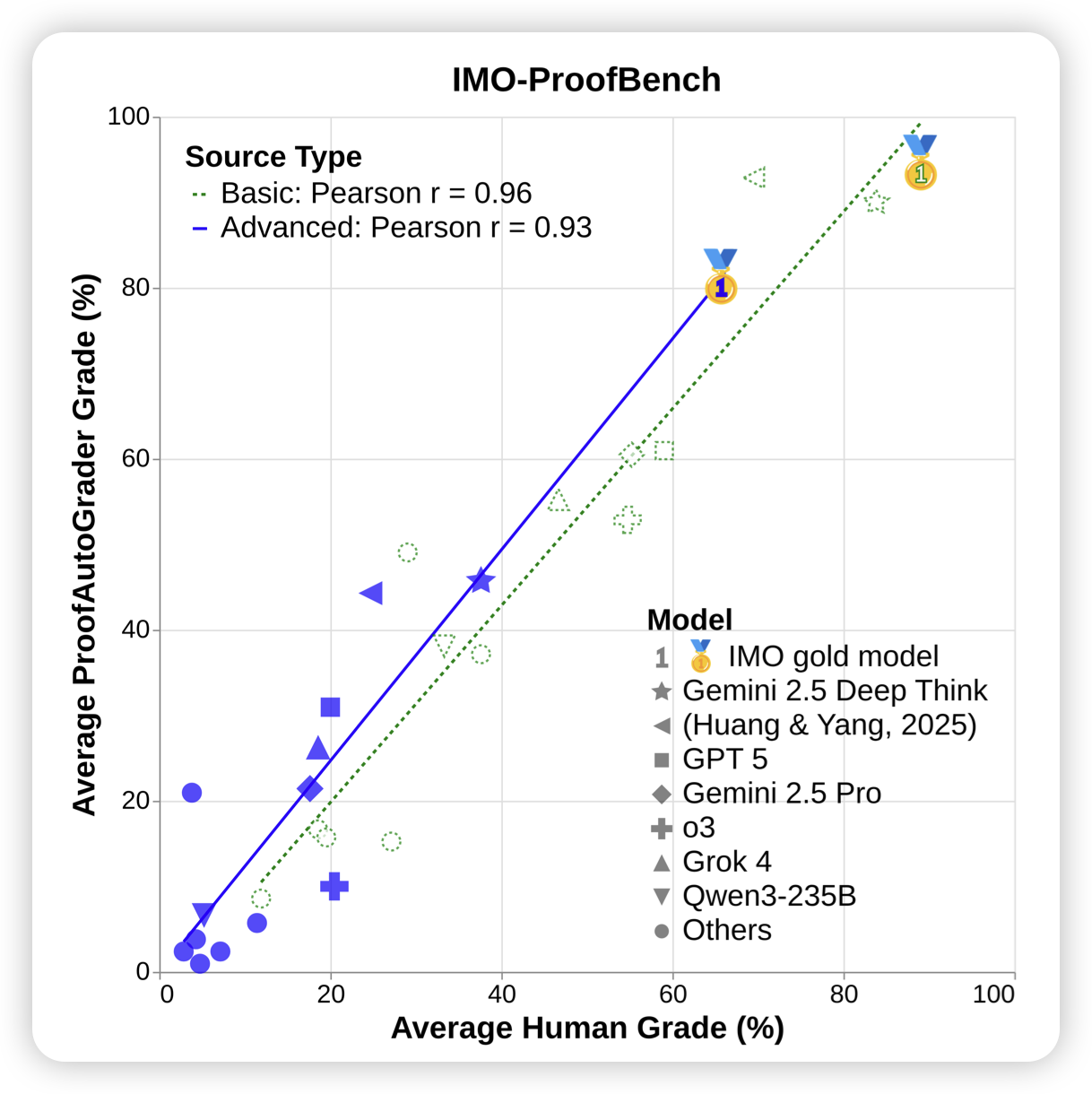
Towards Robust Mathematical Reasoning
思路简单,工作量就不简单。Google的这篇工作,是一个数学证明题的benchmark,作者认为:目前的已有的llm math评测往往都是对答案verify,其实模型的证明题能力并没有增强。所以,作者做了一个包含400证明题的benchmark,然后找数学家一共写了1000份证明正确性的判断,以此又训练了证明判别器来和数学家结果对齐。由此可以在这个benchmark上衡量不同数学模型的证明能力
这个故事感觉已经看了好几遍了,但是这篇工作是结果最solid的