11.11有618篇新论文
SWE-fficiency: Can Language Models Optimize Real-World Repositories on Real Workloads?
一篇工程代码的benchmark工作,但是作者瞄准的是优化场景,而不是debug。作者收集了500个真实仓库里和速度优化相关的issue,这些问题不再是0/1的结果正确性,而是可以判断模型写的优化到底带了多少的加速比

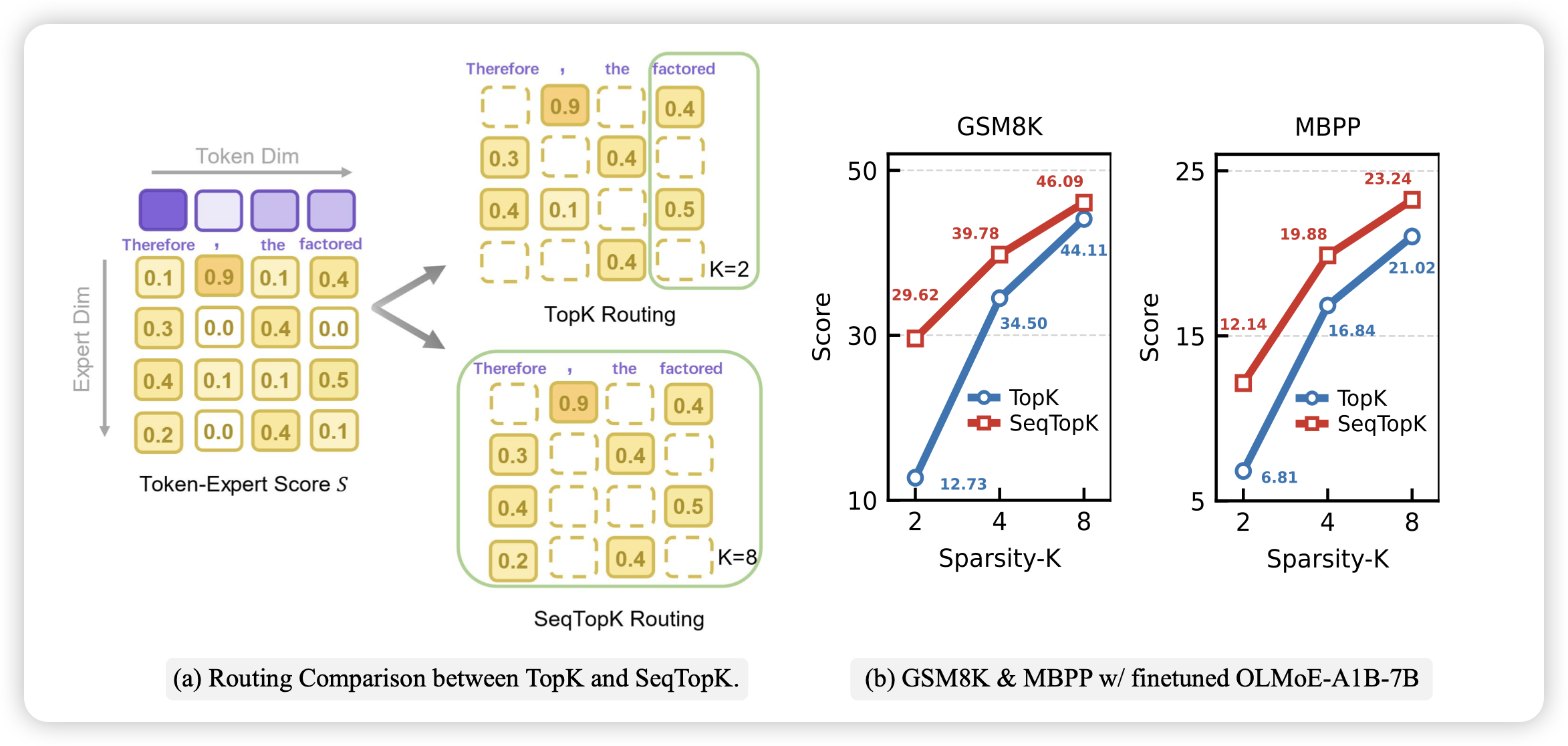
Route Experts by Sequence, not by Token
传统MoE,每个token激活固定数量的专家,也就是说要求每个token的激活数量相等。作者把这个等价扩展到了seq-level:如果不要求每个token稳定激活k个,而是要求每个seq激活len*k个专家呢?在这个逻辑,如果一个token的专家权重都差不多,那这个token激活的专家数量就给多一些。
我感觉这个方向有点像是之前的clip,其实通过更多的global batch token做估计,来区分“难/简单”,可能会演变成batch-level equal等,最后需要训练的btz进一步扩大
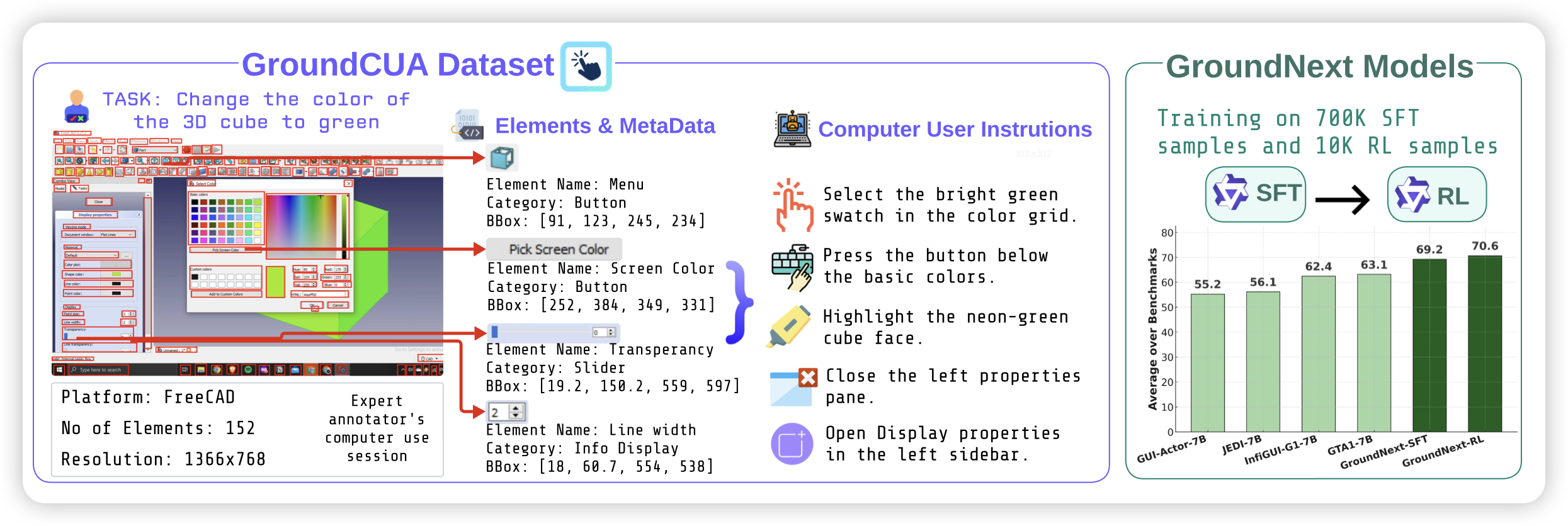
Grounding Computer Use Agents on Human Demonstrations
许久未见的grounding工作,作者标注了3.5M的grounding数据,尤其聚焦了desktop场景