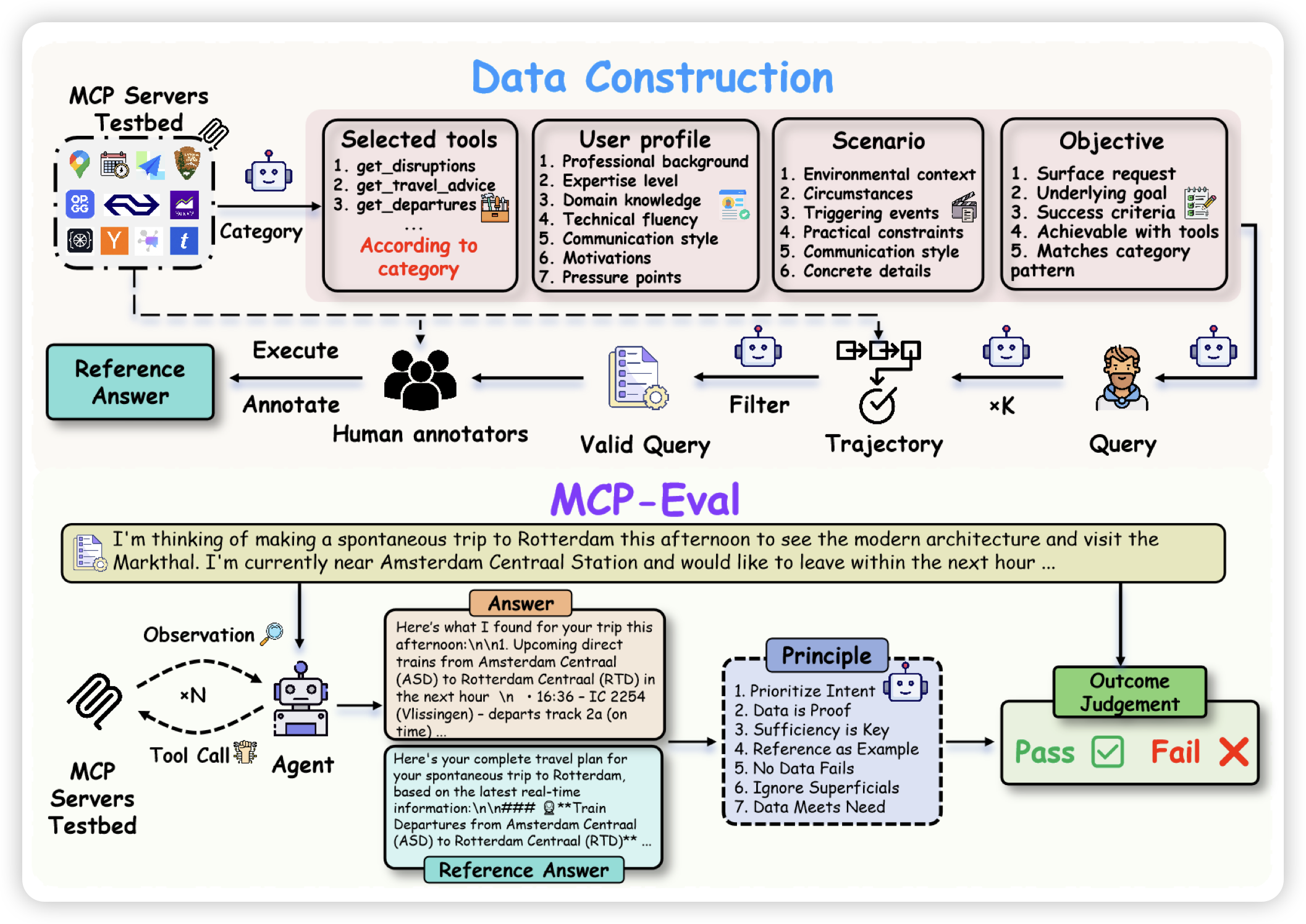
MCP-AgentBench: Evaluating Real-World Language Agent Performance with MCP-Mediated Tools
一篇mcp benchmark工作,首图有点像online-mind2web的风格。发现很多在之前bench上做的很好的模型,在新bench上暴露问题
话说我们之前做过toolbench,感觉这类mcp bench工作一直有个bug在于:缺乏可以定量的judge办法,主流都是对主观任务做llm judge,这种系统一般连接rl以后会快速hack,不知道kimi是怎么搞的