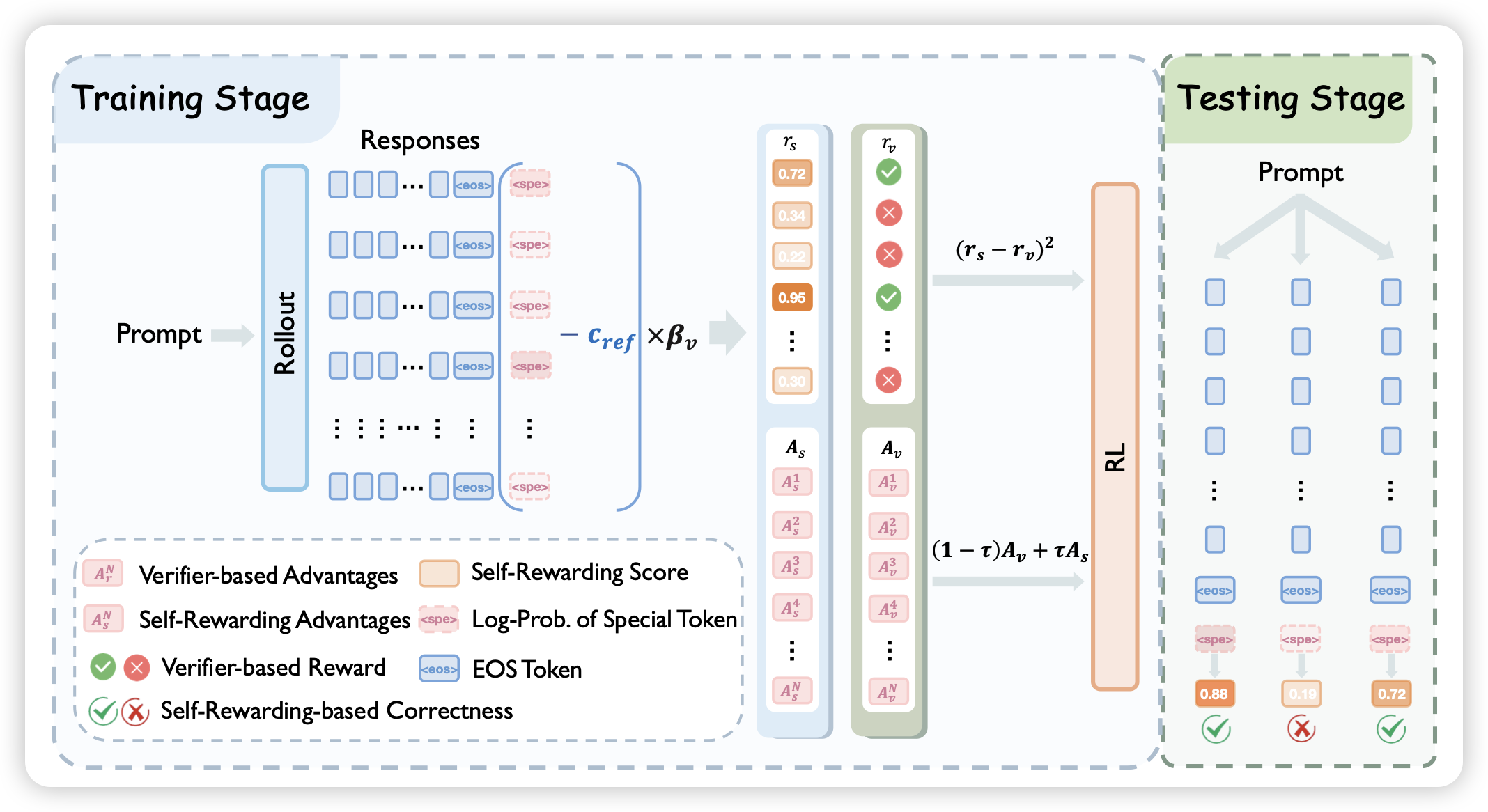
LaSeR: Reinforcement Learning with Last-Token Self-Rewarding
这篇工作比较有趣:作者让rl中的policy先说完response,以后再在eos的下一个token上预测一下reward。训练的时候有一个mse的辅助loss来优化这个reward的准确率。如果可行的话,其实就把policy和reward model统一了起来,可以在infer时让policy说好多次,然后用自己的reward选一个最好的。比较神奇的是,作者发现:在加了这个辅助loss以后,policy部分的表现反而提高了