gpt-oss-120b & gpt-oss-20b Model Card
Gpt-oss model card来了。
不是……模型都开源了,不讲讲怎么训的嘛,只给一大堆评测结果
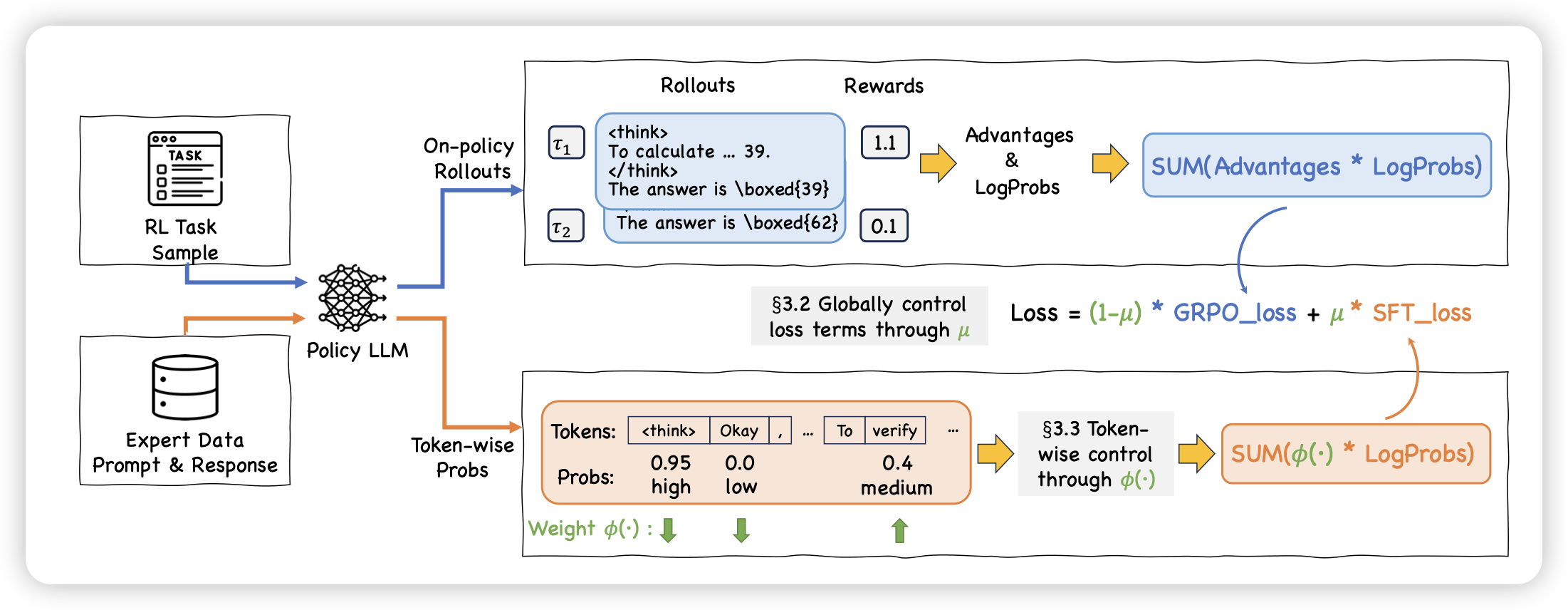
On-Policy RL Meets Off-Policy Experts: Harmonizing Supervised Fine-Tuning and Reinforcement Learning via Dynamic Weighting
这篇工作很妙。作者发现rl和sft在训练上的区别是,一个entropy有权重,一个没有权重。能不能把sft也视为一种rl,然后给他做dynamic weighting呢?作者尝试了一下在每个rollout中,对于query同时使用rollout和load sft数据,然后加权一起训练,发现效果很好
作者这里对sft的采样权就是单纯的p*(1-p),有点神奇。基本上就是训练entropy既不太大也不太小的token。但是这个sft数据加weight的思路挺有趣的