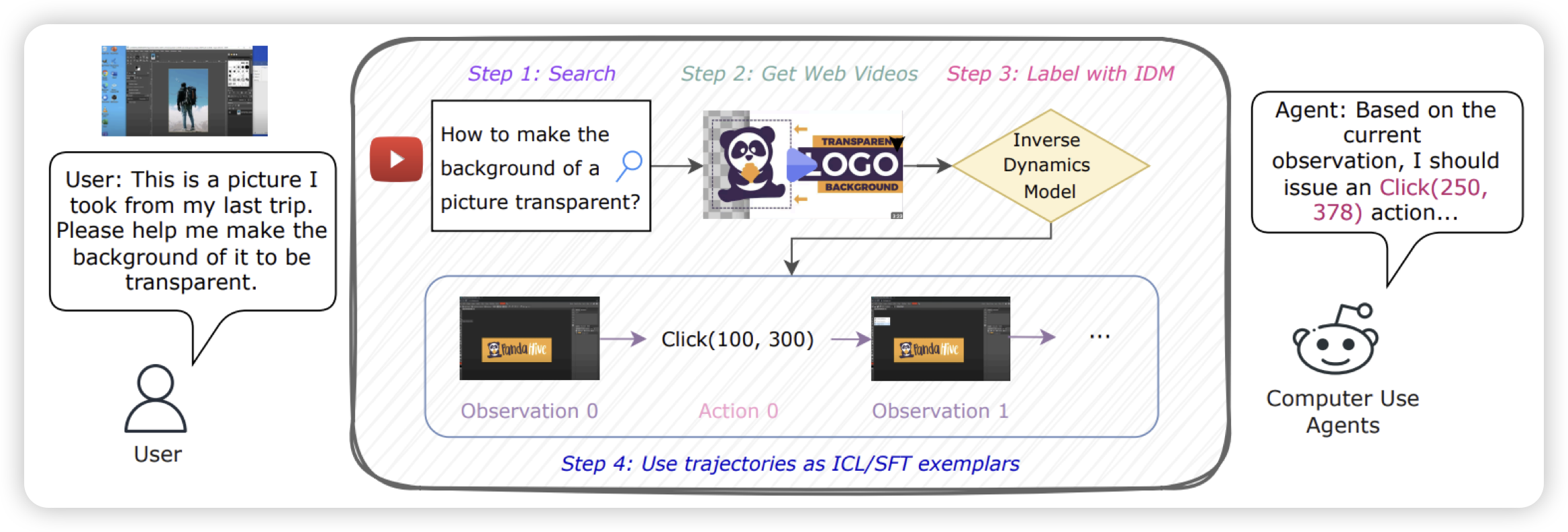
Watch and Learn: Learning to Use Computers from Online Videos
Tutorial-based GUI Agent领域的一篇新工作。但这篇工作里,作者训了一个IDM模型(就是VPT里那个idm),让模型自动从视频里抽取action,由此把视频转化成学习信号更充足的image-text-interleave数据。然后在测试时,训练模型去看着教程来做相似的题目
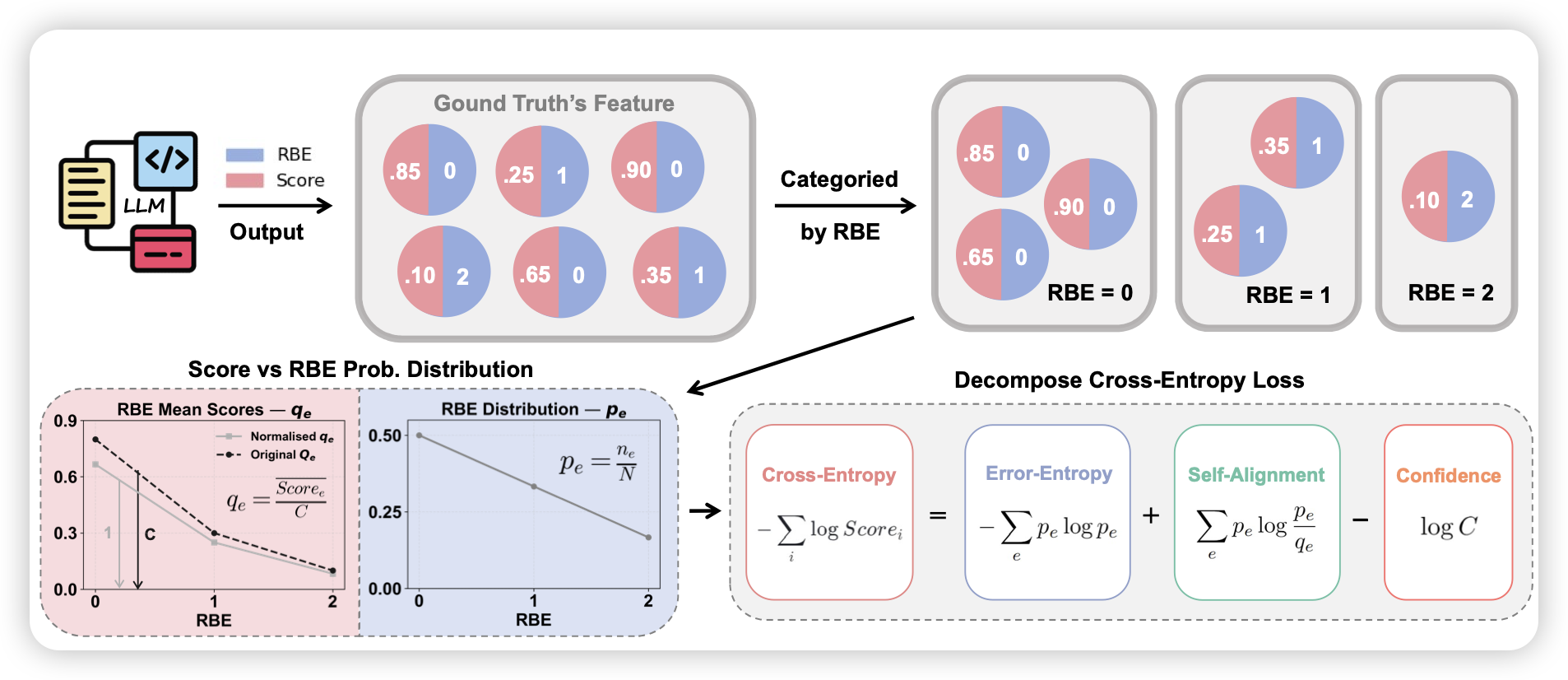
What Scales in Cross-Entropy Scaling Law?
之前有一些predictable scaling领域的工作,认为模型的pretrain crossentropy会随着参数量/训练量的指数上升而线性下降。然而,实际上当模型变得很大时,这个理论就不再成立了,因为crossentropy衰减得更慢。作者发现了其中原因:把crossentropy拆分成三个部分,实际上只有一个部分是可以保持scaling law的,而另外两部分基本和模型大小无关,是常数。
这个方向现在好像研究的人不多了,大家都去卷rl了
GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
GDPval的论文挂出来了。这个benchmark瞄准了AI解决真实世界问题、产生经济价值的水平。openai找了真正的各行业专家来出题和给题目做verify,由此产出了大概1000题,开源了200题。

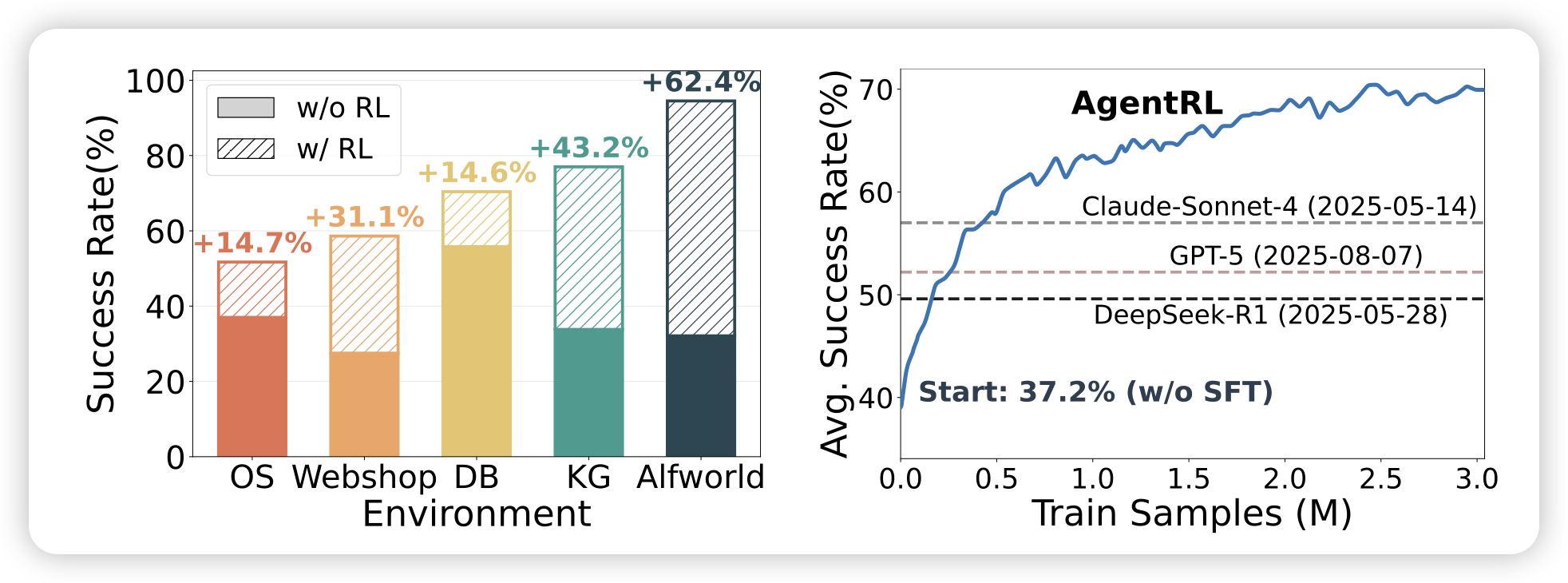
AGENTRL: Scaling Agentic Reinforcement Learning with a Multi-Turn, Multi-Task Framework
zhipu最近发了computerRL,MobileRL,今天又发了一篇agentrl,这篇工作里,作者混训了几个纯文本的agent场景,然后用的是神奇的全异步rollout
这篇有点像是agentbench的后继