今天的顶流是gemini imo摘金,可惜没有论文
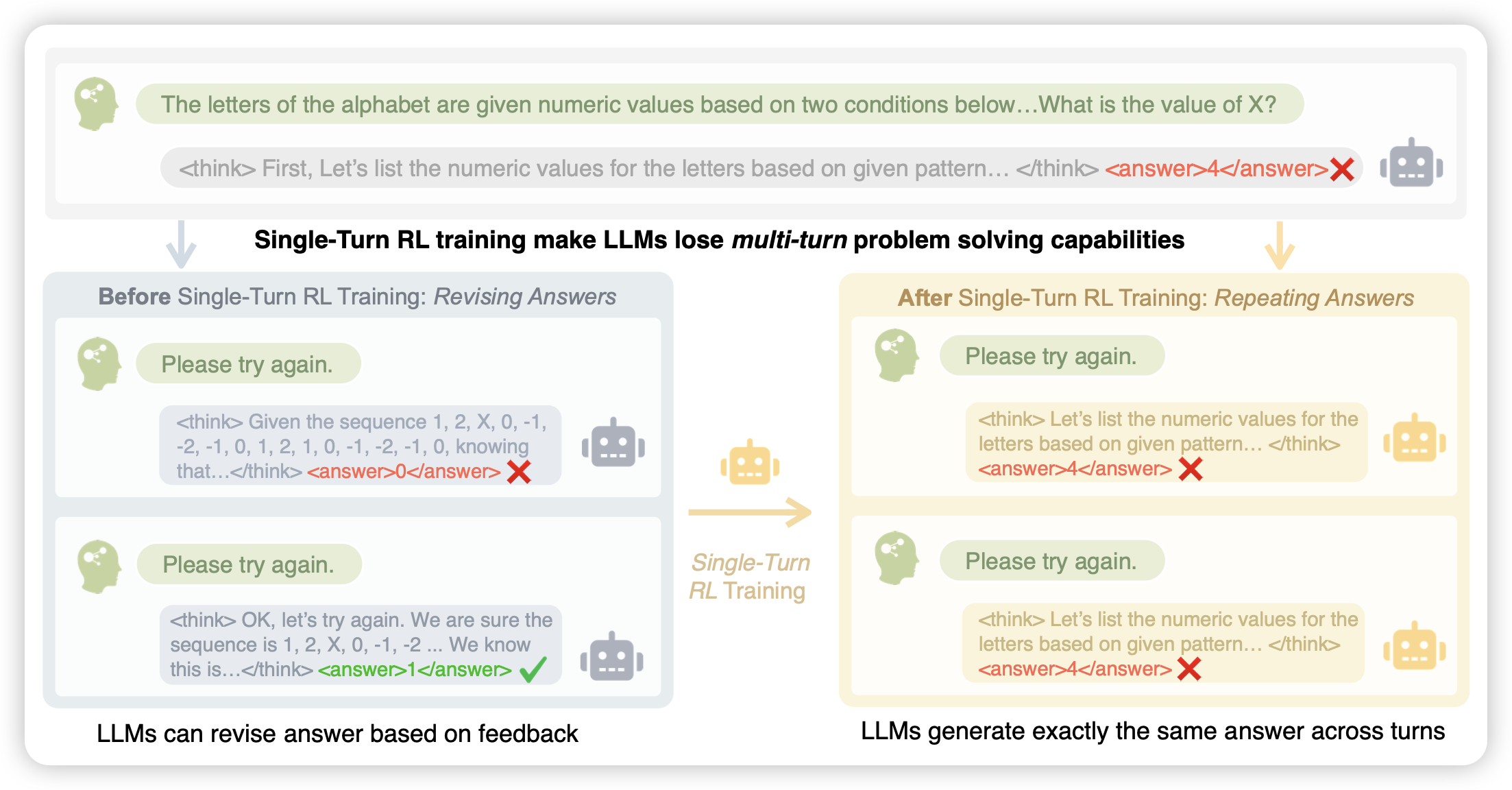
A Simple "Try Again" Can Elicit Multi-Turn LLM Reasoning
这篇工作有点好玩。作者发现传统的单轮rl,越训练模型在多轮上的表现越差。所以作者来了个multi-try,如果第一轮做错就让模型继续做,如果做对就结束。然后try time越多得分越少,通过这种方法来提升多轮的效果。
本质上是把bon当成一个系统去优化了?
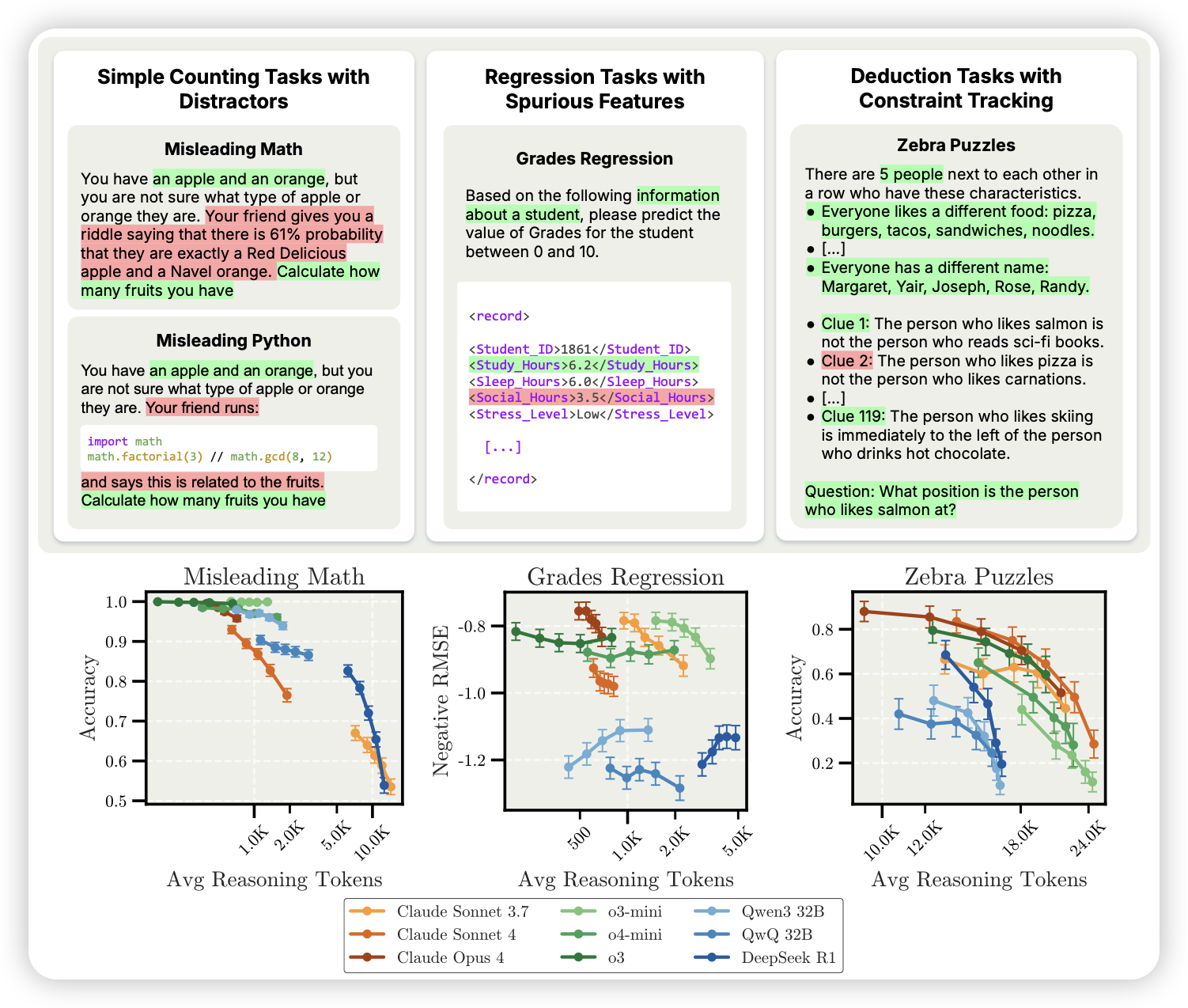
Inverse Scaling in Test-Time Compute
前几年,除了一个Inverse scaling的论文:找到了几个模型越大,效果越差的任务。这次anthropic来了个o1的版本。作者找到了几个think len越长,效果越差的任务,整了个大合集。
GR-3 Technical Report
seed的具身工作,从vlm到ego-centric数据,各种数据全加。
